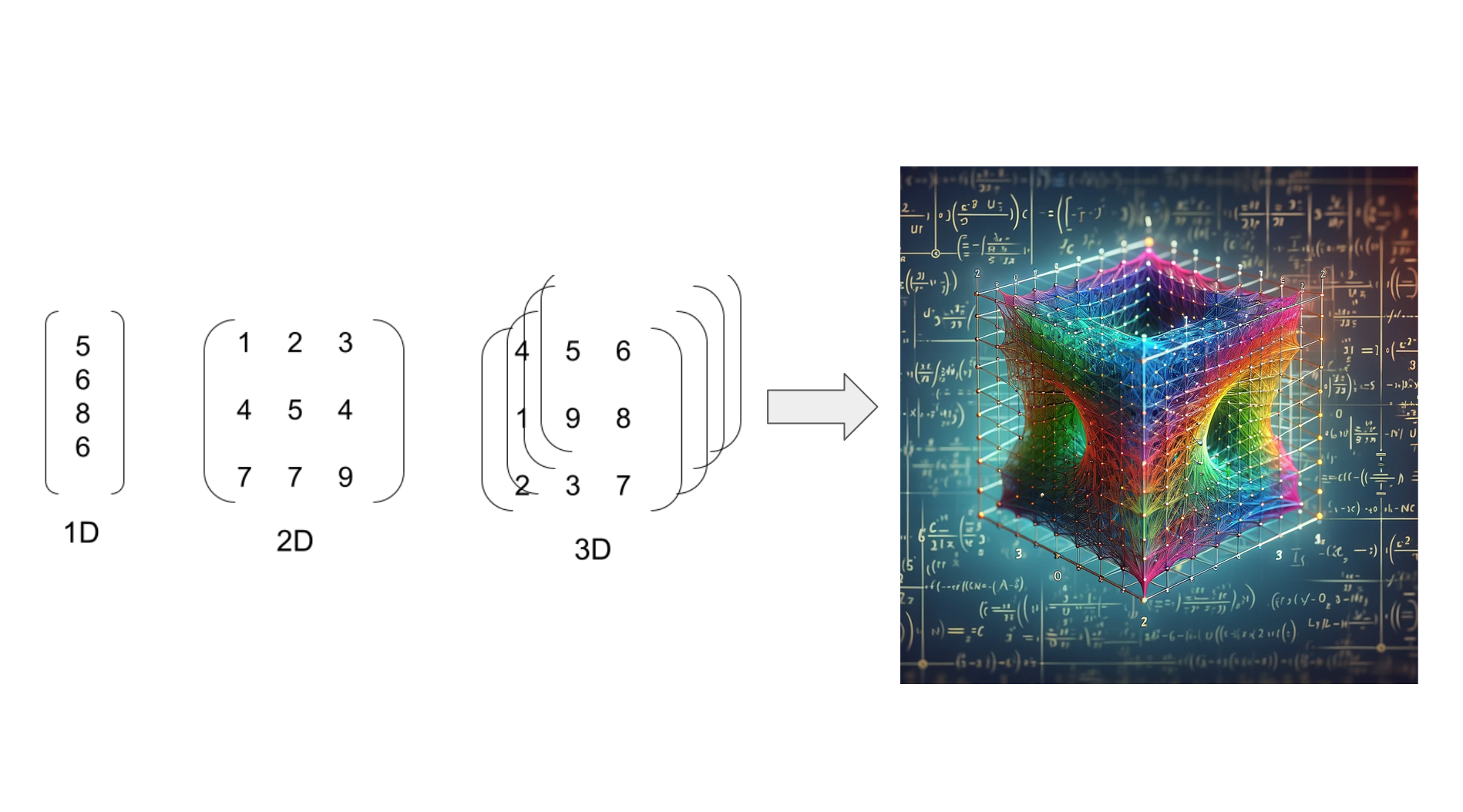
Tensors
Definition
A tensor is a mathematical object that can be considered a generalization of scalars, vectors, and matrices to higher dimensions. In the broadest sense, a tensor is any set of numerical values that transforms according to specific rules when the coordinate system is changed. Here’s a breakdown of how tensors relate to more familiar mathematical concepts:
-
Scalar: A single number. In the context of tensors, a scalar is a tensor of rank 0.
-
Vector: An array of numbers. Vectors are tensors of rank 1. They have both magnitude and direction, and in physics, they often represent quantities like velocity or acceleration.
-
Matrix: A 2D array of numbers. Matrices are tensors of rank 2. They can represent linear transformations or relations between vectors.
-
Higher-Rank Tensors: These are extensions of the concept to more dimensions. A rank-3 tensor, for example, can be thought of as a 3D array of numbers, and higher-rank tensors continue this pattern to more dimensions.
Tensors are fundamental in many fields, especially in physics and engineering, where they are used to describe properties like stress, strain, and elasticity in materials, as well as in the general theory of relativity where the gravitational field is described by a tensor. In computer science and machine learning, tensors are used in deep learning frameworks like TensorFlow and PyTorch, where they represent multi-dimensional arrays of data.
Basic operations with Tensorflow and Pytorch
Firstly we need to import the packages.
import tensorflow as tf
import torchTensorflow
## Creating a 2-dimensional tensor
tensor = tf.constant([[1, 2], [3, 4]])tensor_1 = tf.constant([[1, 2], [3, 4]])
tensor_2 = tf.constant([[5, 6], [7, 8]])
## Adding two tensors
result_add = tf.add(tensor_1, tensor_2)
## Subtract two tensors
result_subt = tf.subtract(tensor_1, tensor_2)
## Multiply two tensors
result_mul = tf.matmul(tensor_1, tensor_2)
## Divide two tensors
result_div = tf.divide(tensor_1, tensor_2)## Reshape Tensor
reshaped_tensor = tf.reshape(tensor, [4, 1])
## Transposing
transposed_tensor = tf.transpose(tensor)
## Slicing Tensors
sliced_tensor = tensor[0, :]## Reducing to a Scalar (Sum)
sum = tf.reduce_sum(tensor)
## Finding Maximum
max_value = tf.reduce_max(tensor)
## Finding Minimum
min_value = tf.reduce_min(tensor)
## Calculating the Mean
mean = tf.reduce_mean(tensor)## Expanding Dimensions
expanded_tensor = tf.expand_dims(tensor, 0)
## Squeezing Dimensions
squeezed_tensor = tf.squeeze(expanded_tensor)
## Concatenation
concatenated_tensor = tf.concat([tensor_1, tensor_2], axis=0)
## Applying a Non-linear Activation (ReLU)
activated_tensor = tf.nn.relu(tensor)
## Applying Softmax (common in classification problems)
softmax_tensor = tf.nn.softmax(tensor)
Pytorch
## Creating a 2-dimensional tensor
tensor = torch.tensor([[1, 2], [3, 4]])tensor_1 = torch.tensor([[1, 2], [3, 4]])
tensor_2 = torch.tensor([[5, 6], [7, 8]])
## Adding two tensors
result_add = torch.add(tensor_1, tensor_2)
## Subtract two tensors
result_subt = torch.sub(tensor_1, tensor_2)
## Multiply two tensors
result_mul = torch.mm(tensor_1, tensor_2)
## Element-wise Multiplication
result_mul_elem = torch.mul(tensor_1, tensor_2)
## Divide two tensors
result_div = torch.div(tensor_1, tensor_2)## Reshape Tensor
reshaped_tensor = torch.reshape(tensor, (4, 1))
## Transposing
transposed_tensor = torch.transpose(tensor, 0, 1)
## Slicing Tensors
sliced_tensor = tensor[0, :]## Reducing to a Scalar (Sum)
sum = torch.sum(tensor)
## Finding Maximum
max_value = torch.max(tensor)
## Finding Minimum
min_value = torch.min(tensor)
## Calculating the Mean
mean = torch.mean(tensor.float())## Expanding Dimensions
expanded_tensor = torch.unsqueeze(tensor, 0)
## Squeezing Dimensions
squeezed_tensor = torch.squeeze(expanded_tensor)
## Concatenation
concatenated_tensor = torch.cat([tensor_1, tensor_2], dim=0)
## Applying a Non-linear Activation (ReLU)
activated_tensor = torch.relu(tensor)
## Applying Softmax (common in classification problems)
softmax_tensor = torch.softmax(tensor, dim=1)
Ragged Tensor
A ragged tensor is a type of tensor that allows for the storage of data with non-uniform shapes or sizes. This contrasts with regular tensors, which require that all dimensions are uniformly sized. Ragged tensors are particularly useful in handling sequences of different lengths, which is a common scenario in various applications, such as natural language processing.
Here are key points about ragged tensors:
-
Irregular Shapes: Ragged tensors can store data with variable lengths in certain dimensions. For example, in a 2D ragged tensor, each row can have a different number of elements.
-
Use Cases: They are especially useful for handling sequences of different lengths, like sentences in text data, where each sentence might contain a different number of words.
-
Implementation in TensorFlow: TensorFlow provides specific support for ragged tensors. You can create a ragged tensor using
tf.RaggedTensorin TensorFlow. -
Operations: Most operations that can be performed on regular tensors can also be applied to ragged tensors, with some adjustments to account for the irregularity in shape.
-
Example in TensorFlow:
import tensorflow as tf ragged_tensor = tf.RaggedTensor.from_row_lengths( values=[1, 2, 3, 4, 5, 6, 7, 8, 9], row_lengths=[3, 2, 4]) # Indicates the number of elements in each row
In this example, ragged_tensor is a 2D ragged tensor where the first row has 3 elements, the second row has 2 elements, and the third row has 4 elements.
Ragged tensors provide a flexible and efficient way to handle non-uniform data, which is common in many real-world datasets and applications.
PyTorch does not have a built-in concept of “ragged tensors” in the same way that TensorFlow does. In TensorFlow, ragged tensors are a specific type of tensor designed to handle variable-length sequences, but PyTorch approaches this problem differently.
For handling variable-length sequences in PyTorch, you typically use one of the following methods:
-
Padding: The most common method is to pad the sequences so that they all have the same length, and then use a regular tensor. This approach often involves additional masking to inform models which parts of the data are padding and which are actual data.
-
Packed Sequences: PyTorch provides
torch.nn.utils.rnn.pack_padded_sequenceandtorch.nn.utils.rnn.pad_packed_sequenceto handle sequences of different lengths more efficiently. This is commonly used in recurrent neural networks (RNNs). -
Nested Tensors: An experimental feature in PyTorch is “nested tensors”, which can be used to represent data of varying sizes. However, this feature is not as mature or widely adopted as TensorFlow’s ragged tensors.
Here’s an example of how you might handle variable-length data in PyTorch using padding:
import torch
import torch.nn.utils.rnn as rnn_utils
# Example data (list of sequences with variable lengths)
data = [torch.tensor([1, 2, 3]),
torch.tensor([4, 5]),
torch.tensor([6, 7, 8, 9])]
# Pad the sequences so they all have the same length
padded_data = rnn_utils.pad_sequence(data, batch_first=True)
# padded_data is now a regular tensor with paddingIn this example, padded_data is a regular PyTorch tensor where shorter sequences have been padded to match the length of the longest sequence. When using this tensor in models, you would typically also provide information about the original lengths of the sequences to ensure proper handling of the padding during processing.
Sparse Tensor
A sparse tensor is a tensor that is predominantly composed of zero or otherwise default values. Sparse tensors are an efficient way to represent and work with data that has a high proportion of such default values, which is common in various types of data such as large matrices in scientific computing, certain types of graphical data, and in machine learning models like recommendation systems.
Key aspects of sparse tensors include:
-
Efficiency in Storage and Computation: By only storing non-zero or non-default values and their corresponding indices, sparse tensors use much less memory compared to dense tensors (regular tensors). This can also lead to computational efficiency, as operations can be optimized to skip the zero or default values.
-
Usage Scenarios: Sparse tensors are particularly useful in scenarios where data has a lot of default values. For example, in a large matrix representing user-item interactions in a recommendation system, most users interact with only a small subset of items, resulting in a matrix with many zeros.
-
Representation: Sparse tensors are typically represented in formats like COO (Coordinate format) or CSR (Compressed Sparse Row format), which are designed to efficiently store and access sparse data.
-
Support in Frameworks: Many computational frameworks, including TensorFlow and PyTorch, support sparse tensors and provide specialized operations for them.
- In TensorFlow, you can create a sparse tensor using
tf.SparseTensor. - In PyTorch, sparse tensors can be created using
torch.sparse_coo_tensor.
- In TensorFlow, you can create a sparse tensor using
-
Example in TensorFlow:
import tensorflow as tf indices = [[0, 0], [1, 2]] # Coordinates of non-zero values values = [1, 2] # Non-zero values shape = [2, 3] # Shape of the tensor sparse_tensor = tf.SparseTensor(indices=indices, values=values, dense_shape=shape) -
Example in PyTorch:
import torch i = torch.tensor([[0, 1, 1], [2, 0, 2]]) # Indices of non-zero elements v = torch.tensor([3, 4, 5]) # Non-zero values size = (2, 3) # Size of the tensor sparse_tensor = torch.sparse_coo_tensor(i, v, size)
Sparse tensors are essential in handling large-scale, real-world data where memory and computational efficiency are crucial. They enable the processing of large datasets that would otherwise be infeasible with dense representations.
Ragged Tensors vs Sparse Tensors
Ragged tensors and sparse tensors are two different ways of handling irregular data structures in computational frameworks, but they serve different purposes and have distinct characteristics. Here’s a comparison of the two:
-
Ragged Tensors:
- Irregular Shapes: Designed for data that has variable-sized dimensions. For example, in natural language processing, sentences have varying lengths, making a batch of sentences naturally ragged.
- Storage: Stores all values, including zeros and non-zeros, but allows for varying lengths in one or more dimensions.
- Use Cases: Commonly used in scenarios where the length of data varies, like sequences of words or time series data with variable timesteps.
- Representation: Each element in a higher dimension can have a different size. In a 2D ragged tensor, each row can have a different number of columns.
- Framework Support: TensorFlow supports ragged tensors natively with
tf.RaggedTensor. PyTorch handles variable-length sequences using other techniques like padding and packed sequences.
-
Sparse Tensors:
- High Sparsity: Optimized for data that is predominantly composed of default values (usually zeros) and only a small fraction of non-default values.
- Storage: Stores only non-default values and their indices, which is memory-efficient for tensors with a high proportion of default values.
- Use Cases: Useful in large-scale problems where most of the tensor elements are default values, like in large graphs, high-dimensional feature spaces, or matrices with many zeros.
- Representation: Has a consistent shape with many default values. In a 2D sparse tensor, every row has the same number of columns, but most values are defaults.
- Framework Support: Both TensorFlow and PyTorch support sparse tensors with specialized data structures and operations.
In summary:
- Ragged Tensors are about handling data with variable lengths within the same dimension (like a list of lists with different lengths).
- Sparse Tensors are about efficiently storing and computing data that has a large number of default values, by only storing the non-default values and their locations.
Both concepts address the efficiency and practicality of working with large and irregular datasets, but they do so in ways that are suited to different kinds of data irregularity.
Variable Tensor
A “variable tensor” generally refers to a tensor that holds variable data and can be used for trainable parameters in models. These tensors are designed to be modified during the training process, such as the weights and biases in neural networks. Here’s a closer look at variable tensors in these two frameworks:
TensorFlow
In TensorFlow, the concept of a variable tensor is represented by tf.Variable. A tf.Variable is used to store mutable, potentially trainable data, typically weights and biases in a model. These variables are optimized during training; their values are updated through backpropagation.
Example:
import tensorflow as tf
# Creating a TensorFlow variable
weight = tf.Variable(tf.random.normal([5, 2], stddev=0.1))PyTorch
In PyTorch, tensors themselves can be marked as variables by setting requires_grad=True. This indicates that the tensor should be part of the gradient computation, and hence, its value can be modified during the training process. In PyTorch, all tensors can potentially be variable tensors, depending on whether they are involved in the computation of gradients.
Example:
import torch
# Creating a PyTorch tensor variable
weight = torch.randn(5, 2, requires_grad=True)Key Points
- Trainable Parameters: Variable tensors are primarily used as trainable parameters within models.
- Gradient Computation: These tensors are involved in gradient computations for optimization during the training process.
- Mutability: Unlike constant tensors, variable tensors are mutable, meaning their values can change over time.
- Framework-Specific Implementation: TensorFlow uses
tf.Variableto define variable tensors, while PyTorch uses therequires_gradattribute on tensors.